



 So, we have already dabbled into Relationships in JPA, in particular One-To-Many and Many-To-One. It is now time to give a look into Many-To-Many, which is very similar to One-To-Many Relationships. So at this point you should have read the previous two tutorials on JPA 2, but if for some reason you don't know what I'm talking about, give a look at these two links, they will help quite a bit:
So, we have already dabbled into Relationships in JPA, in particular One-To-Many and Many-To-One. It is now time to give a look into Many-To-Many, which is very similar to One-To-Many Relationships. So at this point you should have read the previous two tutorials on JPA 2, but if for some reason you don't know what I'm talking about, give a look at these two links, they will help quite a bit:
For this tutorial it is assumed that you have basic knowledge of SQL and relational databases, in particular MySQL. It is also useful to have a MySQL database installed so that you can actually try out the examples that we will be going through in this tutorial. Unit Testing with JUnit is also a bit part for this tutorial aswell, You'll need to understand what it is, and how it is used. Check the previous Tutorial regarding JPA, they should provide enough information to get you started. An IDE like IntelliJ or Netbeans is also recommended is case you want to try out the source code provided. You don't need special powers, if you know basic SQL, JUnit and you have read and understood the previous tutorials you should be fine. The source code used for this tutorial can be found here : https://github.com/jbaysolutions/jpa2tut-many2many .
Many-To-Many, lets start!
Of the 4 types of relationships that exist, we have already talked about the One-to-Many and Many-to-One and most of the background information regarding how a relationship works, and the difference between Unidirectional and Bidirectional relationship. The Many-to-Many relationship isn't much different to the One-To-Many relationship, except for the fact that now we have an extra middle table around there....
The Join Table
Expanding on the example given on the previous tutorial, we had two Entities : Company and Employee. We now delete the Employee table and create a new Entity which is called Client and we say:
a Company can have several Clients and
a Client can have various Companies
When we say this we have a Many to Many relationship between Companies and Clients, and can be represented on a data model like so:
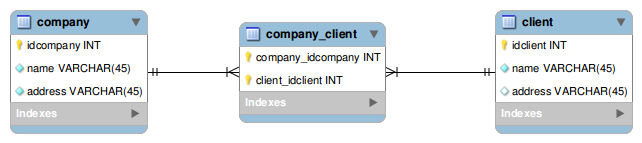
The SQL to create this is like so:
CREATE TABLE IF NOT EXISTS `jpatutorial3`.`company` (
`idcompany` INT NOT NULL AUTO_INCREMENT ,
`name` VARCHAR(45) NOT NULL ,
`address` VARCHAR(45) NOT NULL ,
PRIMARY KEY (`idcompany`) )
ENGINE = InnoDB;
CREATE TABLE IF NOT EXISTS `jpatutorial3`.`client` (
`idclient` INT NOT NULL AUTO_INCREMENT ,
`name` VARCHAR(45) NOT NULL ,
`address` VARCHAR(45) NULL ,
PRIMARY KEY (`idclient`) )
ENGINE = InnoDB;
CREATE TABLE IF NOT EXISTS `jpatutorial3`.`company_client` (
`company_idcompany` INT NOT NULL ,
`client_idclient` INT NOT NULL ,
PRIMARY KEY (`company_idcompany`, `client_idclient`) ,
INDEX `fk_company_has_client_client1` (`client_idclient` ASC) ,
INDEX `fk_company_has_client_company1` (`company_idcompany` ASC) ,
CONSTRAINT `fk_company_has_client_company1`
FOREIGN KEY (`company_idcompany` )
REFERENCES `jpatutorial3`.`company` (`idcompany` )
ON DELETE NO ACTION
ON UPDATE NO ACTION,
CONSTRAINT `fk_company_has_client_client1`
FOREIGN KEY (`client_idclient` )
REFERENCES `jpatutorial3`.`client` (`idclient` )
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
The table that you see serving as a connection between the Company table and the Client table is what is called a "Join Table" , and its sole purpose in life is to keep track of the relations that exist between Company and Client Entities.
The normal notation for a Join Table is to use a single underscore between the name of the two tables that are part of the relation. In our example the expected name of the Join Table would have been companyclient . The Entity that is the Owner of the relationship (you remember what the Owner is, yes?) is placed on the left side of the "".
From this point onwards, when we talk about the Join Table, you know exactly what it is.
Putting it to work
Continuing as we were, expanding from the previous tutorial, we have a CompanyEntity bean that already has a relation with EmployeeEntity, this is a OneToMany relation. We'll leave that as it is for now and proceed to create the ClientEntity bean that is missing, because it was not present on the previous tutorial. If you follow the previous tutorial, it should be pretty easy to get the ClientEntity bean done, but here is a snippet of what you should be aiming for at this moment:
@Entity
@Table(name = "client")
public class ClientEntity implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "idclient")
private Integer idclient;
@Column(name = "name")
private String name;
@Column(name = "address")
private String address;
And now, we define the new relation that we created by adding the following lines to the CompanyEntity bean:
@ManyToMany
private Collection<ClientEntity> client;
And while we are at it, lets go to the ClientEntity bean and add the following:
@ManyToMany(mappedBy = "clientCollection")
private Collection<CompanyEntity> company;
Create in both beans the respective Getters and _Setters _for the collections.
So, what is new so far on these Entities that we haven't seen before on the other tutorials?
@ManyToMany
The ManyToMany annotation works pretty much like the other annotations we have see thus far, the only different is a couple of assumptions that are made because of the Join Table that was created to support the relationship. But lets start from the beginning: Every many to many relationship has obviously two sides: a Owning side and the Inverse side (which is... non-owning).
As you can see, on one of the @ManyToMany annotations that we wrote a minute ago we have a mappedBy element. This mappedBy element is mandatory and must be placed on the Inverse side of the relationship in case we are mapping a Bidirectional. If we are mapping a Unidirectional relationship then the Inverse side would have no_ @ManyToMany annotation and therefore no _mappedBy element. In a second I'll get back to this!
The other possible elements of the @ManyToMany annotation are targetEntity, cascade and fetch, which we have already seen on the previous tutorials. I'll just give a kick overview of the targetEntity element to say that it is optional if the collection is defined using generics, otherwise you have to put it in, example:
@ManyToMany(targetEntity=ClientEntity.class)
private Collection client;
So returning to the mappedBy element, it points out the field (that must exist on the Target Entity, which is known either through the use of generics or through the use of the targetEntity element) that owns the relationship.
Now that we have a better understanding of what was inserted on the Entity bean, lets see how it works.
Working it
In the source code provided with this tutorial there is a Class called ManyToManyTesting, in it we have this method called testCompanyWithClient1 which is annotated with @Test, in it, we have the following:
CompanyEntity c = createTestCompany();
ClientEntity client = createTestClient();
em.persist(c);
em.persist(client);
em.flush();
c.getClientCollection().add(client);
em.merge(c);
em.flush();
Both methods createTestCompany and createTestClient simply create its corresponding Entity Bean with some test data inserted. Nothing is set in relation to relationships on those methods.... they just save us some work when writing the test cases.
So, running this test case we get a successful execution, right? Perfect.
The reason why this was a successful and easy bit of code is because we based all of our previous code on the expected JPA defaults, and because of that all worked wonderfully. Now, in real life:
you might not have a change to decide on the names of the tables and all of that.
you might not want to have the name of the field in a particular way, just to be inline with the defaults
In fact.... this was the first time ever that I personally had a ManyToMany relationship that works based on the defaults.... So, imagine this scenario, instead of having a* Join Table* named companyclient , our Join Table is now called companyhas_client:
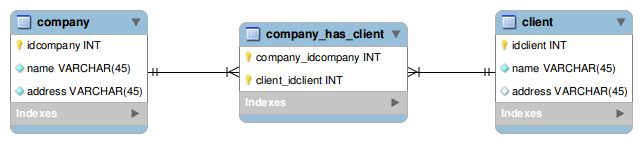
The SQL for this new version of the join table is like so:
CREATE TABLE IF NOT EXISTS `jpatutorial3`.`company_has_client` (
`company_idcompany` INT NOT NULL ,
`client_idclient` INT NOT NULL ,
PRIMARY KEY (`company_idcompany`, `client_idclient`) ,
INDEX `fk_company_has_client_client1` (`client_idclient` ASC) ,
INDEX `fk_company_has_client_company1` (`company_idcompany` ASC) ,
CONSTRAINT `fk_company_has_client_company1`
FOREIGN KEY (`company_idcompany` )
REFERENCES `jpatutorial3`.`company` (`idcompany` )
ON DELETE NO ACTION
ON UPDATE NO ACTION,
CONSTRAINT `fk_company_has_client_client1`
FOREIGN KEY (`client_idclient` )
REFERENCES `jpatutorial3`.`client` (`idclient` )
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
Lets try to run the same test case again and see what happens:
Internal Exception: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'jpatutorial3.company_client' doesn't exist
Error Code: 1146
Call: INSERT INTO company_client (client_idclient, company_idcompany) VALUES (?, ?)
So, our Join Table is actually "companyhasclient" and not "companyclient" as the persistency manager was expecting. The reason why this is looking for the "companyclient" table comes down to the defaults.
Default Join Table
If we were to have the Join Table called "companyclient" instead of "companyhasclient" this would have worked fine, as you have seen, but now it just isn't working and the persistence manager cannot figure out how to work with these Entities. Because we have only placed the minimum amount of data onto the _ManyToMany annotation, and in fact have only used that annotation to represent the existing relationship on the database, we heavily depend on the defaults of JPA to figure out what the names of the columns and tables are. For the two Entities we have: CompanyEntity and ClientEntity, we have annotated them with** @Table and the name of the table they represent. A Join Table between these two entities, by default, is expected to be the name of the table on the annotation @Table of the Owning side Entity, underscore, name of the table on the annotation @Table** of the Inverse side Entity. Some readers might be lost now, so look at the following example:
@Table(name = "store")
public class StoreEntity
and
@Table(name = "product")
public class ProductEntity
The default expected Join Table, if StoreEntity was the Owning side and ProductEntity the Inverse side, would be : store_product To use the a non default, unexpected join table there is this other annotation, which is very conveniently called: @JoinTable
@JoinTable
The @JoinTable annoration is used on the Owning Entity side of the relationship and is used to describe to the entity manager where to look for the Join Table and what to expect once it needs to use it. Lets jump on it and modify now our owning entity CompanyEntity like so:
@JoinTable(name="company_has_client")
@ManyToMany
private Collection<ClientEntity> client;
Now, lets run again the unit test and Bang: Success again! Simple, yes? But wait.... There is more! As per usual, an explanation of this new annotation and a description of all possible elements will follow, but lets go for it while we perform some more changes, ok? Let us now change the name of the field of our Owning side Entity CompanyEntity like this:
@JoinTable(name="company_has_client")
@ManyToMany
private Collection<ClientEntity<strong>clientCollection</strong>;
Modify the getters and setters accordingly please. Also go to ClientEntity and modify it like so:
@ManyToMany(mappedBy = "clientCollection")
private Collection<CompanyEntity> company;
So that it is referencing an existing field on the Owning side Entity. Lets run the unit test one more time:
Internal Exception: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException:
Unknown column 'clientCollection_idclient' in 'field list'
Error Code: 1054
Call: INSERT INTO company_has_client (clientCollection_idclient, company_idcompany) VALUES (?, ?)
bind =[2 parameters bound]
We get an exception and I've also made a particular point of putting in Bold the interesting bit about this exception. Basically, you can see that the generated SQL is referencing a column that does not exist, it is called clientidclient and not** clientCollectionidclient. The reason it is looking for a column in the Join Table** that is called clientCollection_idclient is once again due to the defaults. The name of the column that is in bold was created by using the name of the field on the Entity bean : "clientCollection" , underscore, and the column name of the _@Id _field on the specified target entity:
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "idclient")
private Integer idclient;
So, we have to expand our example now to take into account that we are using names of columns that are not what the manager is not expecting. To do this we look a bit further into the @JoinTable annotation.
@JoinTable expanded
As you have seen before the @JoinTable is used to map associations through the use of a Join Table, and by specifying the particularities of such table. We have seen how to specify a Join Table that does not follow the expected naming convention that is used by the persistency manager, but this is not all that can be done with it. For the JoinTable annotation one can specify the name of the join table by using the name element. the name of the schema that table belongs to through the use of the schema element, and the name of the catalog through the use of the catalog element. This is the easy bit, and almost self explanatory. The new'ish bit is specifying the join columns through the use of the following elements:
joinColumns : The mapping of the join columns whose field is defined on the Inverse Entity.
inverseJoinColumns : the mapping of the join columns whose field if defined on the Owning Entity.
Both these elements are JoinColumn arrays. For our example we have modified the name of the field client to clientCollection. This field is specified on the Owning side Entity but is referent to the Inverse side Entity. Yes? Recapping:
@JoinTable(name="company_has_client")
@ManyToMany
private Collection<ClientEntity> clientCollection;
This bit exists on the Owning side (CompanyEntity) and the field clientCollection references the Inverse side (ClientEntity), correct? Because of this, we use the inverseJoinColumns element to define the join columns whose name does not match the default generated as explained before. Modify the CompanyEntity bit that was written before this this version now:
@JoinTable (name = "company_has_client",
inverseJoinColumns {
@JoinColumn(name = "client_idclient", referencedColumnName = "idclient")
}
)
@ManyToMany
private Collection<ClientEntity> clientCollection;
Run the test again and as you can see everything works fine now! The inverseJoinColumns element is an array of @JoinColumn annotations, which we have already seen in a previous tutorial, but still, it should be pretty self explanatory as for the elements used in our scenario. But lets go ahead and modify our example a little bit more and modify now the ClientEntity class with the following:
@ManyToMany(mappedBy = "clientCollection")
private Collection<CompanyEntity> companyCollection;
So, we are changing the name of the field on the Inverse side that references the Owning side. Please modify the Getters and Setter methods and Getters and Setter methods and run the unit test again.
Internal Exception: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException:
Unknown column 'companyCollection_idcompany' in 'field list'
Error Code: 1054
Call: INSERT INTO company_has_client (client_idclient, companyCollection_idcompany) VALUES (?, ?)
bind =[2 parameters bound]
As expected, the same problem as before, and to fix it we now use the joinColumns element because this field is specified on the Inverse side but references the Owning Entity. Modify the** @JoinTable** annotation to look like so:
@JoinTable(name = "company_has_client",
joinColumns {
@JoinColumn(name = "company_idcompany", referencedColumnName = "idcompany")
},
inverseJoinColumns = {
@JoinColumn(name = "client_idclient", referencedColumnName = "idclient")
}
)
@ManyToMany
private Collection<ClientEntity> clientCollection;
Run the unit test again and get a fully successful running test unit! And, to close off this tutorial, I'll just mention the remaing element of the** @JoinTable annotation, which is the uniqueConstraints element. The uniqueConstraints element is an array of @UniqueConstrain** and is used to specify the constraints that are to be placed on the table, but just if table generation is being used, which is not the case here.
Finishing off....
Hope you enjoyed and this tutorial was of use to you. As per usual, if you find that this article is incorrect in anyway or if you have any comment to give, either good or bad, drop a comment over here.
Follow Up
JPA 2 Tutorial – Many To Many with Self